GraphQL
페이스북에 의해 REST 구조를 개선하기 위한 방식으로 개발된 시스템
구조
기존 REST는 우측과 같이 서버에서 데이터를 가져올때 연관된 요청을 모두 요청 해야한다. 하지만 그 과정에서 항상 모든 정보가 쓰이진 않으며 처리될때 어떤 정보를 받게될지 명확하지 않다.
이점을 개선하여 SQL 과 같이 필요한 정보만을 타입 과 데이터 구조를 요청하게 된다.

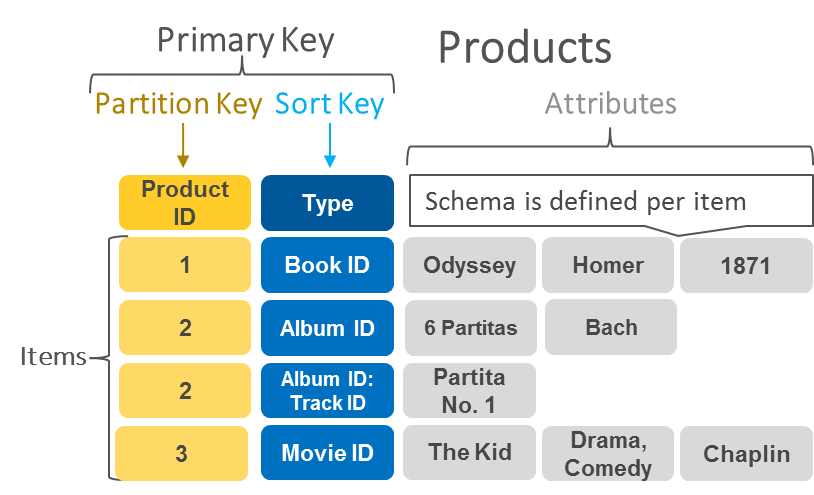
내부 구조는 간단히 키워드로만 구성된 계층구조로 조회하는 형태로 보인다.
상세한 구조는 document에 심층적으로 소개되어있으니 그걸 참조
{
hero {
name
}
}
{
"data": {
"hero": {
"name": "R2-D2"
}
}
}
장단점
REST의 일부 단점을 개선 하였지만 그렇다고 완벽한것은 아닌것
알아서 상황에 맞는 구조로 설계하기
장
- 필요한 데이터만 요청
- 어떤 데이터구조가 이용될지 명확
- 한번의 요청으로 필요한 데이터 조회가능
단
- 기존 http 캐싱 구조를 사용할 수 없음
- 파일 업로드의 명확한 구현이 되어있지않음
- 요청 필터링의 어려움
사용될 데이터를 요청할때 구조가 정의되는 탓에 항상 최적의 데이터를 조회한다고 볼수없기때문
- 구조가 복잡해지는 문제
- 이미 REST 구조로도 처리가 가능한 경우가 존재
Written with StackEdit